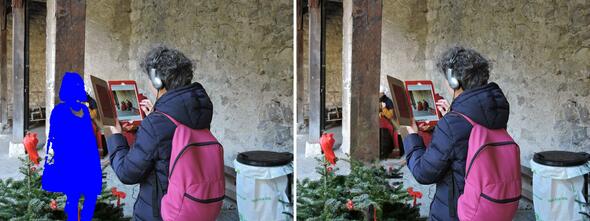大連理工大学とAdobe Researchの研究チームが開発した「High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling」は、画像内の物体を除去する深層学習を用いた手法だ。

物体を除去するにあたって、消した欠落領域を埋めるように修復するインペイント方式を採用する。インペイント方式は、これまでも研究されており、例えば「PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing」[2009 et al.Barnes] は、他の類似する部位(パッチ)を見つけて貼り付けるテクスチャ合成アプローチを採用している。しかしながら、これでは新規コンテンツを生成する能力がないため、似ている箇所がないと対応できない。
これに対応するため、最近の研究では深層学習ベースのアプローチにシフトしている。例えば、「Context encoders: Feature learning by inpainting」[2016 et al.Pathak] は、画像のコンテキストを理解し欠落領域用にもっともらしい画像を生成する学習を教師なしで行う。シーンの欠落領域を周囲の環境から予測するCNN(Convolutional Neural Network)である。このような学習ベースのインペイントは複雑な欠落領域の埋める作業に大きな改善をもたらしたが、しかしながら、この方法では高解像度画像を除去する場合、欠落領域が広くなるにつれ視覚的アーティファクトがどうしても目立ってしまう。
この課題に挑戦するため、本モデルでは欠落領域を埋める際に精度の高い箇所のみ埋めて、残りは次のターンで徐々に埋めていく反復アプローチを採用する。
このやり方を行うために、信頼度マップを生成し、この信頼度マップを参考に欠落領域の内側にある信頼度の高いピクセルだけを埋めていき、次の繰り返しターンで残りのピクセルを更新するように訓練する。つまり、前回に埋めた領域を既知のピクセルと認識し再利用することで、信頼度の低い領域を段階的に改善していく。GAN(Generative Adversarial Network)に基づいた生成アプローチを採用している。
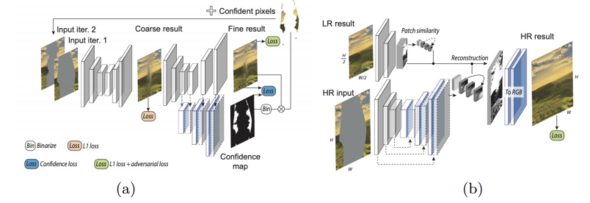
反復的に埋めていくモデルは、低解像度で学習されるため、高解像度入力に直接適用するのは理想的ではない。この問題を解決するために、2倍の高解像度のインペイント結果を生成するためのアップサンプリングネットワークを導入する。
このネットワークは、Generative Image Inpainting with Contextual Attention [2018 et al.Yu] を拡張したもので、パッチの類似性を学習するためのモジュール、画像再構築のためのモジュールから設計される。ネットワークは、入力画像中の高解像度の特徴パッチを借用することで実現する。
利点として、欠落領域の画像はパッチのみを用いて構築されるため、コピーしたくない領域を除外したり、埋めることに使用する参照領域を指定したりして、結果を調整できる。
学習用に、オブジェクト形状の欠落領域を持つ画像のデータセットを2パターン収集した。(1)欠落領域が前景のオブジェクトに重なっている場合、(2)欠落領域が背景にのみ表示されている場合。
これにより学習したモデルは、元画像とマスクを入力に高解像度で違和感の少ないインペイント画像を出力する。
出力した結果は、定量的および定性的な評価の両方において、既存の手法を大幅に上回った。以下の画像では、いくつかの出力結果を確認できる。