中国科学院、ボストン大学、TAL Education Group、カーディフ大学、香港城市大学による研究チームは、動画内の人の動きを別の動画内の人に転移し動かしてしまうGAN(Generative Adversarial Network)を使った研究「Human Motion Transfer with 3D Constraints and Detail Enhancement」を発表した。

ターゲット動画(動かされる側)内の人の外観を維持したまま、ソース動画(動かす側)の人の動きを模倣した合成映像を生成する。
このようなGANを使って動画内の人物の動きだけを他の動画内の人物へ転移する技術は、2018年に「Everybody Dance Now」[Chan et al. 2018] が発表している。画像内に写る人物の関節と骨格を検出する「OpenPose」を使用してソース動画内の人の姿勢情報を抽出し、取り出した姿勢情報をターゲット動画に転移させて合成映像を生成するアプローチだ。
さらに一歩進んで、動きの検出に「OpenPose」と「DensePose」の両方を使って精度を向上させた「Video-to-video synthesis 」[Wang et al. 2018] も登場した。
次に登場したのが、ネットワークの条件に3次元情報を加えることで、精度を上げた技術「Liquid Warping GAN」[Liu et al. 2019] だ。ソース動画の人物とターゲット動画の人物の姿勢情報と外見情報を切り離して、再結合し模倣した動画を生成するアプローチを採用し、この時に再構成された3D人体モデルの投影をGANの条件として精度を上げた。
次に登場したのが今回紹介する本技術。3D情報も使いつつ、さらに細部を補正することに重点を置いたアーキテクチャを採用する。ターゲット映像の人物の細部まで維持したまま、ソース映像の人物の動きを模倣した合成映像を生成する。
ネットワークは、合成画像を生成するMotion Transfer Net (MT-Net)と細部を向上させるDetail Enhancement Net (DE-Net)の2段階で構成される。
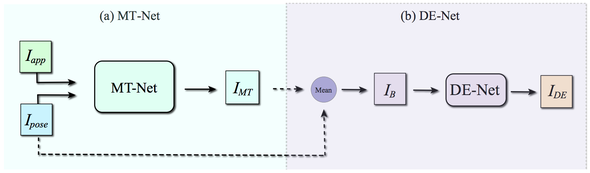
MT Netでは、ターゲット画像(Iapp)とソース画像(Ipose)を入力として、ターゲット画像(Iapp)と同じ外観を持ち、ソース画像(Ipose )と同じポーズを持つ画像 IMTを出力する。
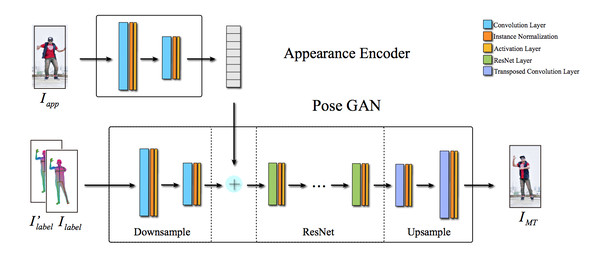
MT Net内では、ターゲット画像の外観の特徴を抽出しPose GANの条件とする。ソース画像から人物の3Dモデルを再構成し、それを2Dに適応してラベル画像を作成したものを、Pose GANの入力条件している。
Pose GANでは、2つの識別器を用いて生成器で作成した画像を判定させ、IMTを出力する。この時点では歪みなどのアーチファクトを多く含んでいるので、DE Netに入力して細部を向上させる。
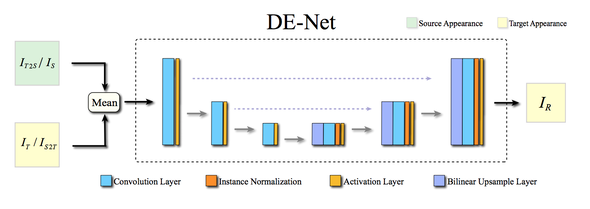
DE-NetではU-netが用いられる。MT Netで出力したIMTとソース画像を混ぜ合わせたモノをUnetの入力とし、最終的な画像を出力する。
以下の比較画像でも分かるように、これまでの類似研究に比べ、ターゲット動画内の人物のアイデンティティを細部ベースで維持しつつ、動きの転移に成功している。
