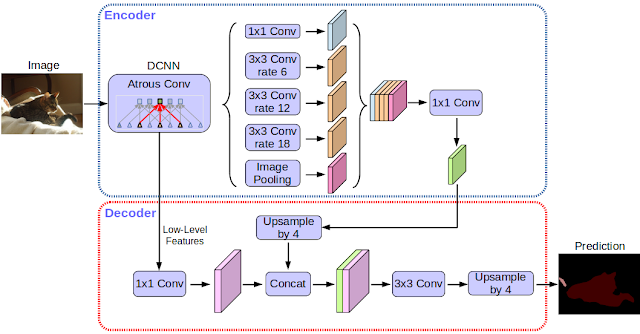
Googleは、同社機械学習ライブラリTensorflow実装の画像セマンティックセグメンテーションdeep learningモデル「DeepLab-v3」をオープンソースにて発表しました。
GitHub:models/research/deeplab at master · tensorflow/models

セマンティックセグメンテーションは、画像をピクセルレベルで把握し、各ピクセル1つひとつを画像内の各オブジェクト、例えば「道路」「空」「人」「犬」などのオブジェクトクラスに意味付けし割り当てることです。各オブジェクトの境界にあたる輪郭を正確に特定します。
今回発表されたDeepLab-v3は、前回のv2に比べ、改良したatrous空間ピラミッド型プーリング(atrous spatial pyramid pooling、ASPP)、Atrous畳み込みを用いるモジュールを採用し、精度を向上させています。