OpenAIは、失敗から学ぶ強化学習アルゴリズム「HER(Hindsight Experience Replay)」と、そのアルゴリズムを使用して物理ロボットで動作するモデルを訓練するための8つのシミュレートされたロボット環境を発表しました。
訓練するロボット環境には、Fetch researchプラットフォームとShadowHandロボットが含まれます。ロボットアームが物体を操作するいくつかのタスクが用意されており、どれも目標であるゴールが設定されゴールに向かって動作します。
例えば、以下の画像は、黒のパックを押すように弾いて赤丸(ゴール)に停止させるというタスクが行われます。
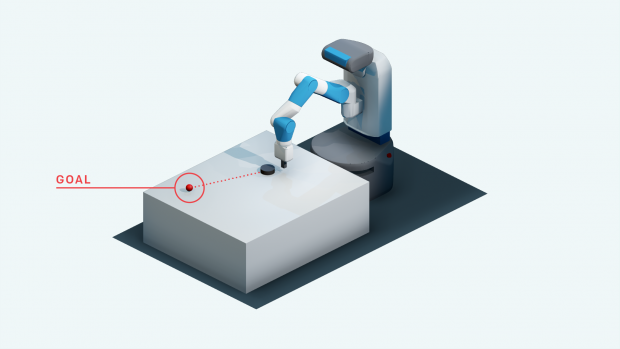
HERの特徴は、仮にゴールと違う場所に黒パックが停止した場合でも、それはそれで成功と置き換えて学習します。違う場所へ黒パックがスライドしたとしても、そこをバーチャルゴールとして再設定することで今後へ生かすと。
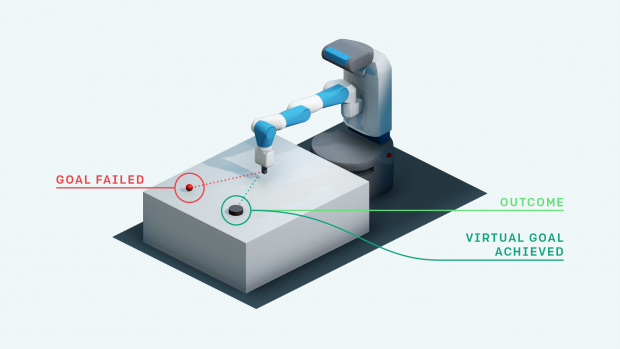
もともとバーチャルゴールに目標が設定してあれば成功していたということを後付けで解釈することで、今後すべてのゴール達成へ役立てます。
もともと達成しようとしていたゴールでなかったとしても、このプロセスを繰り返すことで、最終的に達成したい目標を含め任意の目標を達成する方法を学ぶことができるとします。
HERのコードは、OpenAIが公開しているbaselinesにて公開しています。

関連
OpenAI、同団体デフォルト強化学習アルゴリズム「PPO」をリリース。Boston Dynamicsのような人型ロボットシミュレーション環境でもポリシーを最適に訓練可能 | Seamless