東京大学 篠田・牧野研究室の研究者らは、動画に含まれる画像や音から機械学習を用いて適切な触覚情報を推定し視聴者に提供するモデル「VibVid」を論文にて発表しました。
VibVid: VIBration Estimation from VIDeo by using Neural Network
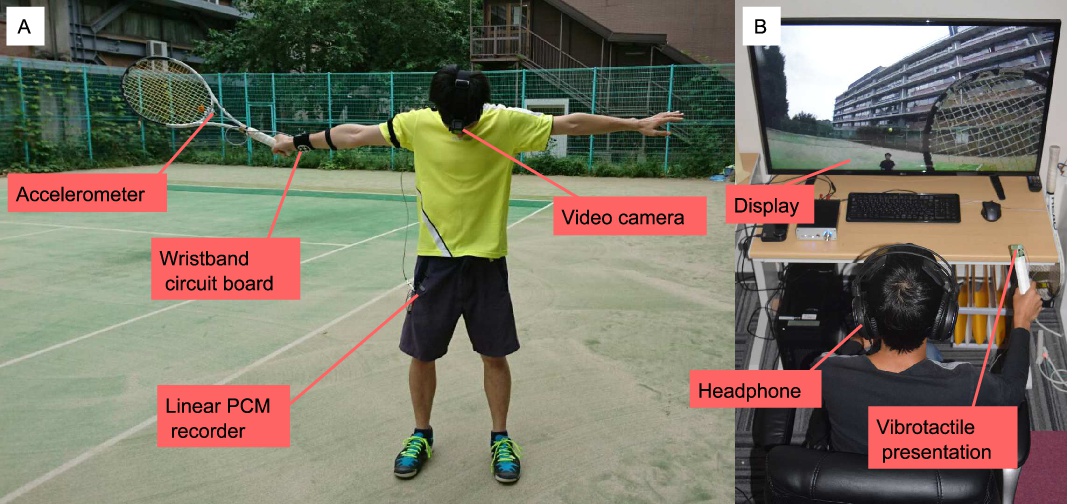
(左図:テニスの画像、音、加速度を記録するためのデバイスを装着した様子。右図:手に触覚が得られるラケットを持ち体験する実験中の被験者。)
本稿では、画像フレームと音データを含むビデオから適切な加速度を推定し、視聴者に正確な振動触覚を与える事でより質の高い視聴体験を提供するニューラルネットワークモデルを提案します。
一例として、テニスの一人称視点ビデオからテニスラケットに伝達する振動を推定し、付与することによって評価した実験を行います。
モデルを作成するにあたり、まずカメラやリニアPCM(Pulse-Code Modulation)レコーダ、加速度計などを装着したテニスプレイヤから、画像フレーム、音データ、加速度データを取得し記録します。
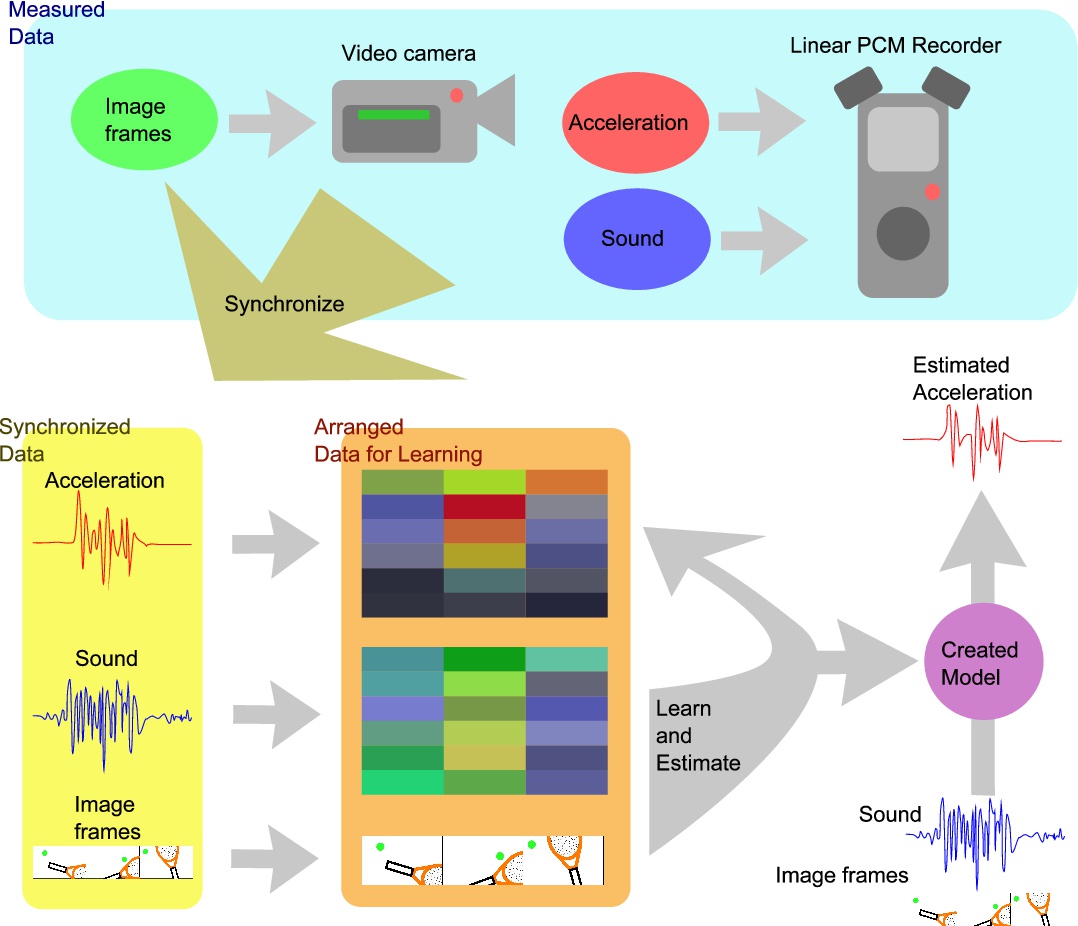
(本提案手法の概要図)
次に、画像と音から振動を推定するモデルを作成します。推定の前処理として、画像データはダウンサンプリングし、音データと加速度データはSTFT(短時間フーリエ変換)を用いて変換します。そして、画像フレーム、音データの2つを統合し、全結合層を介して振動を推定します。
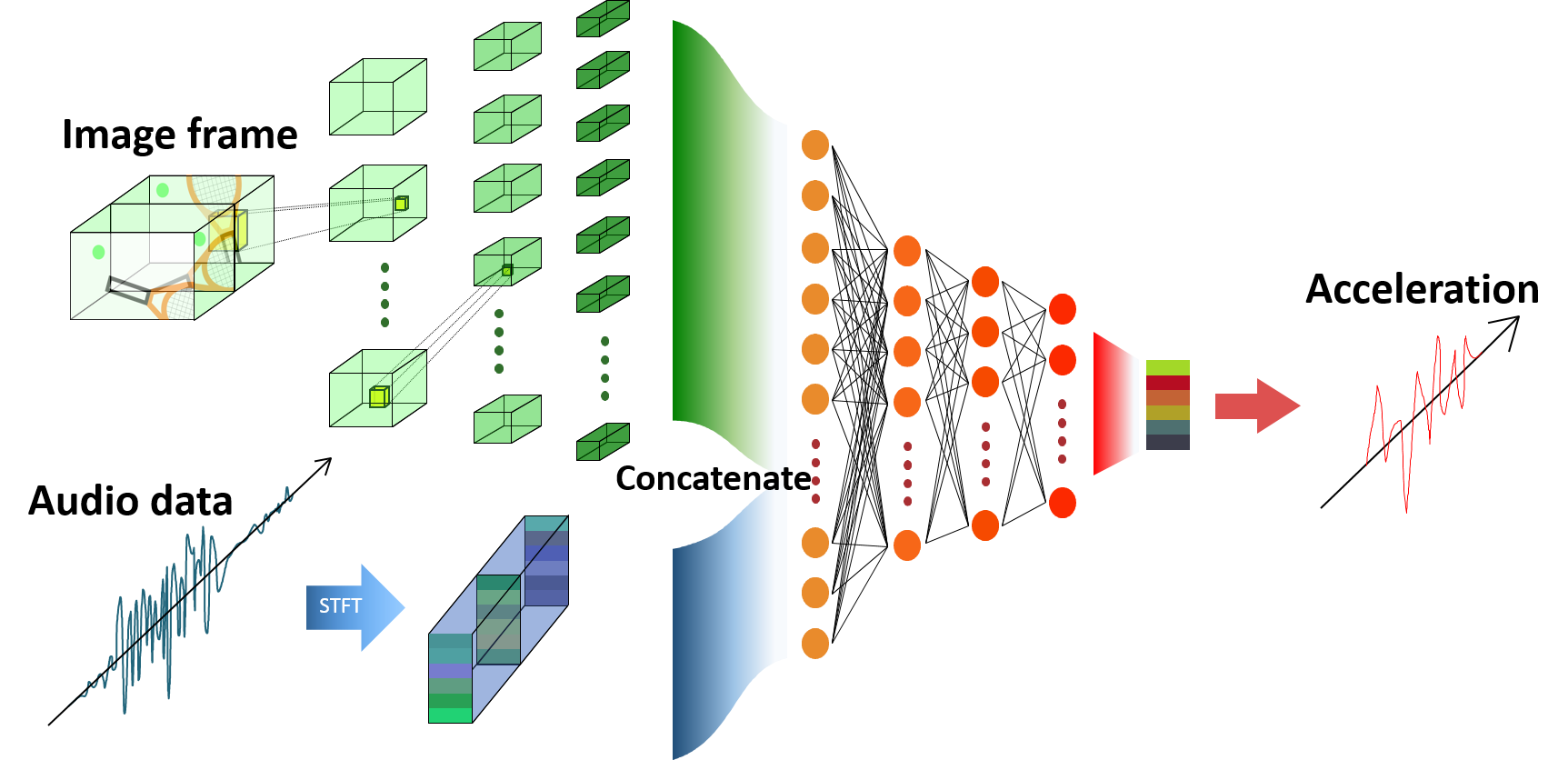
(ニューラルネットワークの概要図)
その結果、本提案手法で生成した波形は実際の振動波形とほぼ一致し、20人の参加者アンケートから適合度、楽しさ、没入感、心地よさ、現実感の5つで良好な結果を示しました。

関連
東京大学、隣り合って離れた2人が「触覚付きAR」を裸眼と素手でリアルタイムに空中操作できる超音波ベースの視触覚クローンシステムを論文にて発表 | Seamless