Elon Musk氏などが設立した人工知能を研究する非営利団体「OpenAI」は、英国のオックスフォード大学、米国のカリフォルニア大学バークレー校、カーネギーメロン大学の研究者らと共同で、強化学習において他のエージェントの学習プロセスを考慮しながら学習する「LOLA(Learning with Opponent-Learning Awareness)」を論文にて発表しました。
Learning with Opponent-Learning Awareness(PDF)
本提案は、従来の強化学習とは違ってマルチエージェントにおいて、他のエージェントの動作を察知しながら学習します。
例として「囚人のジレンマ」が使用されます。囚人のジレンマとは、2人の共犯者が捕まり、一方が自白すると自分は無罪になって仲間が3年の刑、両方が自白すると両方が2年の刑、両方が黙秘すると両方が1年の刑、になるというゲーム理論のモデルです。
従来の強化学習では、軽い1年の刑を選択するため両者黙秘に確信度が高まります。一方で、本提案「LOLA」では、相手を意識するため一方が自白することに確信度が高まります。

(Cが自白でDが黙秘。)
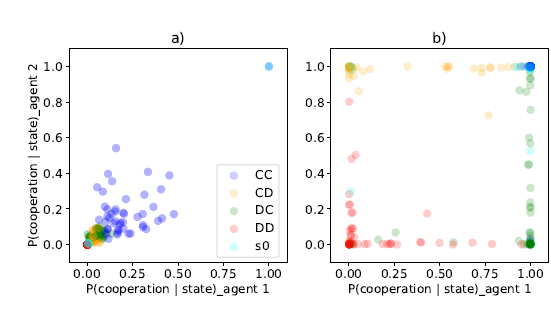
( a)が従来でb)が本提案。従来では両者黙秘のCCに確信度が高く、LOLAでは一方が自白に確信度が高い。)