Google Researchは、スマートフォンに基づいた機械学習による視覚認識技術において、スマートフォンが大量の電力消費を必要とせずに画像をよりよく認識できるよう支援するTensorFlowベースのモデルセット 「MobileNets」をオープンソースとしてリリースしました。
現在、Google Cloud Vision APIを通して、スマートフォンで捉えた画像から、分類したり、個々の物体や人の顔を検出したり、画像内に含まれているテキストを検出し読み取ったり、画像カタログのメタデータ作成、不適切なコンテンツの管理、画像の感情分析といったモバイルにおける機械学習モデルの視覚認識技術を提供しています。
こういった、従来のモバイルアプリ内で学習している多くのコンピュータは、処理のためにデータをクラウドサービスに渡し、非常に強力なコンピュータで処理、戻ってユーザーに提供しています。
それにより、スマートフォンで情報を処理する負担を軽減していますが、一方で待ち時間が長かったり、プライバシーといった欠点を抱えています。
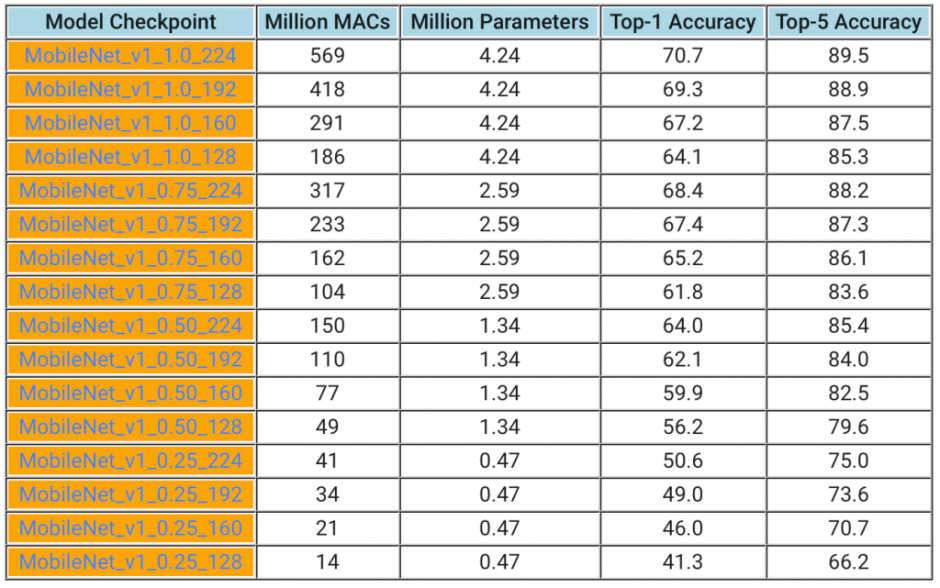
そこで、今回リリースした 「MobileNets」は、機械学習をスマートフォンだけで処理し素早く提供することでその欠点を解決します。それは、レイテンシ、サイズ、精度をトレードオフし、バッテリー消費を低減した低消費電力を実現しており、小規模、低遅延、低電力のモバイルファースト・コンピュータビジョンモデルとして機能させます。
ユースケースとしては、検出、分類、属性、地理的ローカリゼーションなどが含まれます。
本モデルは、今年4月に公開されたこちらの論文がベースとなっています。
MobileNetsのGitHubページはこちら。今回の発表ページはこちら。
関連
Microsoft、オープンソース機械学習ライブラリ「CNTK」のバージョン2.0をGitHubにて公開。Python Kerasサポートなどより使いやすいツールへ | Seamless