Microsoft Research、リーハイ大学、ラトガース大学、デューク大学の研究者らは、テキストによる説明文から画像を生成する機械学習を用いた手法を発表しました。
論文:AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
著者:Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan4, Xiaolei Huang, Xiaodong He
本稿は、抽象的なテキスト記述からイメージを生成することを可能にする「Attentional Generative Adversarial Network(AttnGAN)」と呼ぶ機械学習を用いたアルゴリズムを提案します。
例えば、黄色い体、黒い翼、短いくちばしの鳥といったキャプションをテキストで記述したとして、以下のような画像を生成します。

出力される画像は、コンピュータによってピクセルごとにゼロから作成されるため、この鳥が現実世界に実在するのではなくコンピュータが描画するイメージだと述べます。
提案技術であるAttnGANは、
「GAN(Generative Adversarial Network)」モデルが用いられており、テキスト記述からイメージを生成する生成器と、生成されたイメージの品質を判断する識別器の2つの部分から構成され、品質を向上させます。イメージとキャプションのペアについて訓練されます。
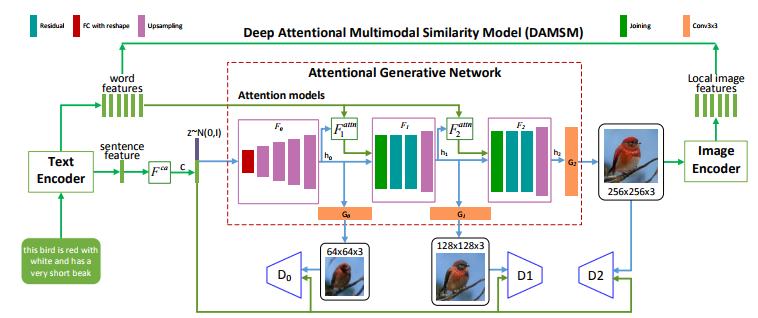
出力結果は、まだまだ不完全で複雑な入力になると品質は下がるなど、発展途上ではあるものの、従来のテキストから画像を生成する技術と比較すると約3倍品質が向上したとしています。
関連
香港城市大学ら、手描きスケッチから法線マッピングを推論する敵対生成学習(Wasserstein GAN)を用いた手法を発表 | Seamless