慶應義塾大学の研究者らは、VRヘッドマウントディスプレイを装着しているユーザーの表情の種類とその強度を機械学習で認識、推定し、アバターに反映させる技術「AffectiveHMD」を論文にて発表しました。
AffectiveHMD:組み込み型センサを用いた表情認識とバーチャルアバターへの表情マッピング(PDF)
本稿では、HMDの内側と外周部に反射型光センサを組み込み、HMDを装着したユーザーの表情を認識する技術を提案します。また、ニューラルネットワークを利用して表情と表情の強さを表す表出強度を識別・推定し、アバターへ反映させる提案をします。

HMDに組み込んだ反射型光センサ群は、発光部から赤外光を照射し反射光を受光することで、顔表面との距離を計測することができます。この計測値を元に機械学習によって表情を認識します。反射型光センサは、安価で小型、軽量かつ低消費電力であることから、HMDに容易に組み込めます。
提案手法では、計測したセンサ値から2種類のニューラルネットワークが表情(本稿では自然、喜び、怒り、驚き、悲しみの5種類が対象)と、その表出強度(例えば、笑顔でも満面の笑みなのか微笑なのか)をそれぞれ、識別・推定します。
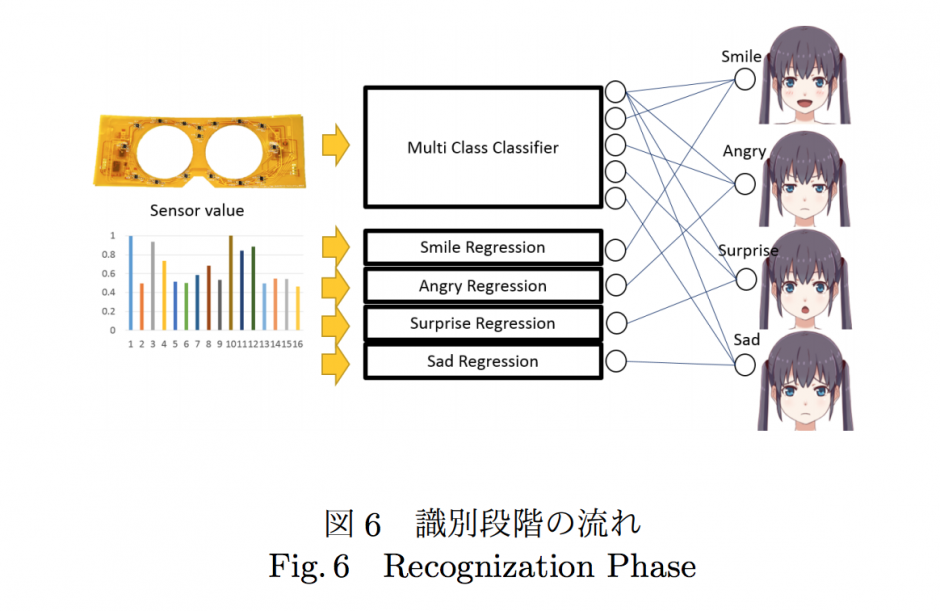
表出強度を考慮したユーザーの表情のアバターへの反映は、例えば以下の図のようになります。

このことで、HMDを装着したユーザーの表情をアバターに反映させることで身体投射性を高められると期待されます。

関連
清華大学、単一のRGB-Dカメラで「まぶた」の動きをリアルタイムに追跡し、眼球および顔の動きと統合することでより詳細な顔面運動を再現する論文を発表 | Seamless